
용어 정리
기술 통계
- 자료의 내용을 압축하여 설명하는 방법을 일컫는다. 요약통계라고도 칭한다.
- 대표적인 통계량에는 평균, 표준편차 등이 있다.
탐색적 데이터 분석
- 데이터 시각화를 아울러, 정량적인 수치로 전체 데이터의 특징을 요약하거나 이해하기 쉬운 그래프를 사용하는 데이터 분석 방법을 일컫는다.
기술 통계 구하기

- describe() 메서드는 기본적으로 수치형 열에 대한 요약 통계를 보여 준다.
- count : 누락된 값을 제외한 데이터 개수를 나타낸다.
- mean: 평균을 구해준다.
- std: 표준편차를 구한다.
- min: 최솟값을 구한다.
- 50% : 중앙값을 구한다.
- 25%와 75%: 순서대로 늘어 놓았을 때 25% 지점과 75% 지점에 놓인 값을 구한다.
- max: 최댓값을 구한다.

- 3장에서 배운 불리언 배열과 sum()함수를 활용하여 도서권수가 0인 행 개수를 구했다. (총3206권)
- 도서권수가 0보다 큰 행들을 ns_book7에 저장하고 요약통계를 구해본다.
- percentiles 매개변수는 원하는 위치의 값을 보게 해주는데 여기서는 40%,60%,90%에 위치한 값을 지정한 것이다.

- include 매개변수에 데이터 타입을 지정하면 다른 데이터 타입의 기술통계를 볼 수 있다.
여기서는 object 타입 열에 대한 통계를 구해보았다. - count행 - 누락된 값을 제외한 데이터 개수
- unique 행 - 고유한 값의 개수
- top 행 - 가장 많이 등장하는 값
- freq 행 - top 행에 등장하는 항목의 빈도수
평균 구하기

- 평균을 구하는 방법은 for 문과 range 함수를 사용하여 구하는 방법과 mean() 메서드를 사용하는 방법이 있다.

- 중앙값을 구할 때는 median() 메서드를 사용한다.
- 데이터 개수가 짝수일 때는 가운데 두 개의 값을 평균하여 중앙값을 결정한다.
- 중복값을 제거하고 중앙값을 구했을 때 대출건수에 중복된 행이 제거되며 중앙값이 커졌음을 확인할 수 있다.
- 중앙값과 함께 자주 사용되는 통계량은 최솟값과 최댓값으로 min()메서드와 max() 메서드를 통해 구할 수 있다.
분위수 구하기
- 분위수란 데이터를 순서대로 늘어 놓았을 때 균등한 간격으로 나누는 기준점이다.
- quantile() 메서드를 사용한다.
- 두 지점 사이에놓인 특정 위치의 값을 구할 때는 보간법을 사용한다.
#분위수에 상관없이 무조건 두 수사이의 중앙값을 사용
pd.Series([1,2,3,4,5]).quantile(0.9,interpolation='midpoint')
#두 수 중에서 가까운 값을 사용
pd.Series([1,2,3,4,5]).quantile(0.9,interpolation='nearest')
- 이 코드는 1,2,3,4,5 다섯 개의 숫자가 있을 때 90%위치에 있는 값을 각각 midpoint와 nearest의 보간법을 사용한 것이다.
백분위 구하기
Q: 남산 도서관 대출 데이터에서 대출건수 10이 위치한 백분위를 찾는법
borrow_10 = ns_book7['대출건수'] < 10
borrow_10.mean()
ns_book7['대출건수'].quantile(0.65)- 불리언 배열을 통해 대출건수 열의 값이 10보다 작은지 비교하기
- mean()메서드를 호출하여 평균을 구한다.(10보다 작은 값이 차지하는 비율을 얻을 수 있음)
- quantile()메서드에 백분위를 넣어 직접 확인한다.
분산과 표준편차, 그리고 최빈값
- 분산은 평균으로부터 데이터가 얼마나 퍼져있는지를 나타내는 통계량이다.
- var() 메서드를 사용한다.
- 표준편차는 분산에 제곱근을 한 것으로 수식 기호는 s를 사용한다.
- std()메서드를 사용한다.
- 최빈값은 데이터에서 가장 많이 등장하는 값을 의미한다.
- mode() 메서드를 사용한다.
데이터프레임에서 기술통계 구하기
- 통계를 구할 때는 수치형 열만 연산이 가능하다.
- 그러므로 해당 열에만 적용이 가능하도록 numeric_only 매개변수를 True로 지정해야 한다.
ns_book7.mean(numeric_only=True)산점도 그리기
- 두 변수(또는 특성) 값을 직교 좌표계에 점으로 나타내는 그래프
- matplotlib 패키지 내 scatter() 함수를 사용한다.
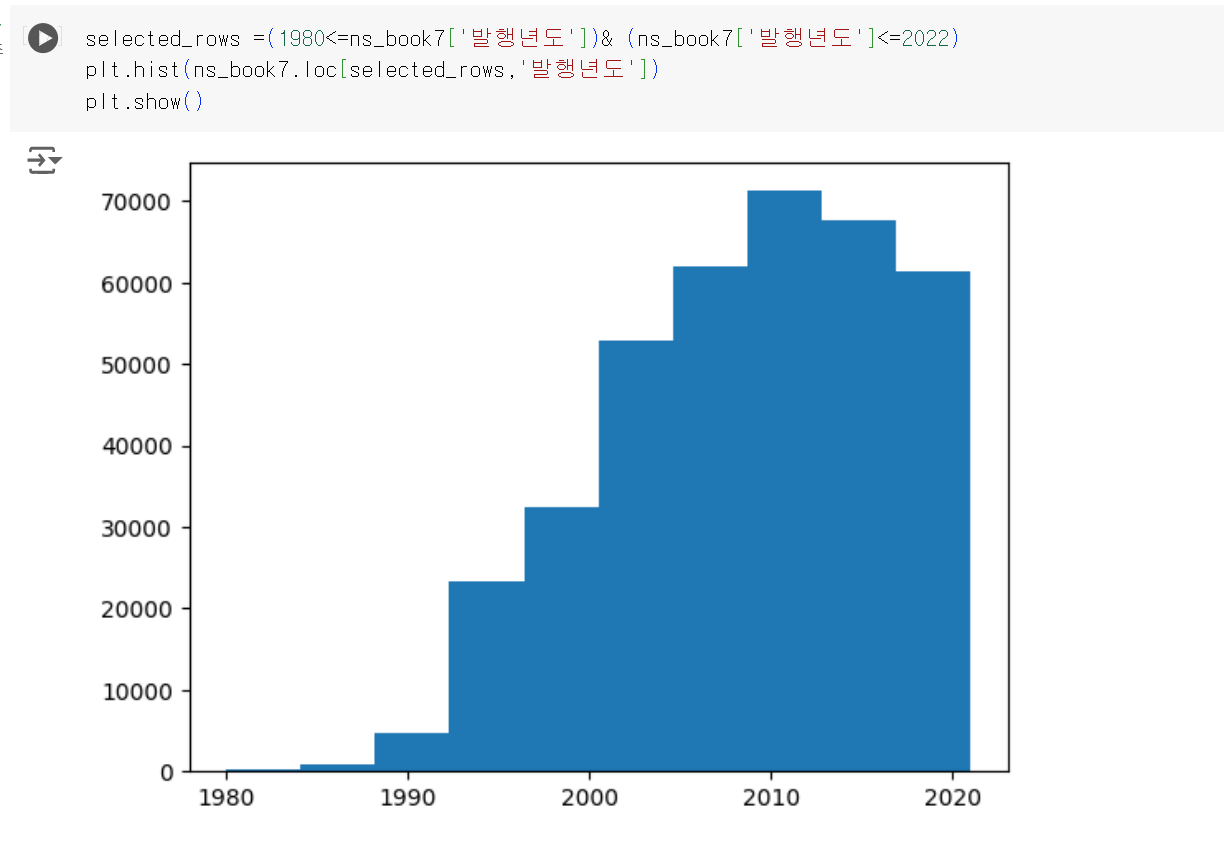
히스토그램
- 수치형 특성의 값을 일정한 구간으로 나누어 구간 안에 포함된 데이터 개수를 막대 그래프로 그린 것이다.
- 구간 안에 속한 데이터 개수를 도수라고 한다.
- matplotlib 패키지 내 hist() 함수를 사용한다.
- bins 매개변수를 통해 구간을 설정할 수 있다.
- 구간이 어떻게 나누어졌는지 확인하기 위해서는 numpy 패키지 내 histogram_bin_edges() 함수를 사용할 수 있다.
히스토그램에 나오는 구간과 도수를 표로 요약한 것을 도수분포표라 하고 도수분포표는 다음과 같이 표현할 수 있다.
| 구간 | 도수 |
| 0~5 | 10 |
| 5~10 | 20 |
| 10~15 | 30 |
| 15~20 | 15 |
정규분포와 표준정규분포
- 가운데가 볼록하고 평균을 중심으로 대칭인 분포를 정규분포라 칭한다.
- 평균이 0이고 표준편차가 1인 정규분포를 표준정규분포라 칭한다.
구간조정하기
- 구간을 조정할 경우는 한 구간의 도수가 너무 커서 다른 구간에 도수가 표시되지 않을 때 한다.
- 로그스케일로 바꾸어 적용할 수 있다.
- 다시 말해, 축에 로그 함수를 적용하여 큰 값의 도수를 줄임으로써 작은 값과의 차이를 줄이도록 하는 것이다.
- xscale() 또는 yscale()함수에 log를 지정하여 사용할 수 있다.
상자 수염 그리기
- IQR 이상치: 제1분위수(25% 백분위수)와 제3사분위수(75%백분위수) 사이의 거리를 의미한다.
- boxplot() 함수를 사용한다.
- vert() 매개변수를 False로 지정시 수평으로 상자 수염 그림을 그릴 수 있다. 이때 x-y축이 바뀌기 때문에 로그 스케일도 x축에 지정해야 한다.
- whis() 매개변수를 통해 수염의 길이를 조정할 수 있다. (기본 수염의 길이: IQR의 1.5배)
숙제
p.279 5번 풀고 인증하기
'공부 > python' 카테고리의 다른 글
| 혼자 공부하는 데이터 분석 6주차: 복잡한 데이터 표현하기 (0) | 2024.08.18 |
|---|---|
| 혼자 공부하는 데이터 분석 5주차: 데이터 시각화하기 (0) | 2024.08.11 |
| 혼자 공부하는 데이터 분석 3주차: 데이터 정제하기 (0) | 2024.07.21 |
| 혼자 공부하는 데이터 분석 2주차: 데이터 수집하기 (0) | 2024.07.14 |
| 혼자 공부하는 데이터 분석 1주차: 데이터 분석을 시작하며 (0) | 2024.07.07 |